MMTR-Bench: Multimodal Masked Text Reconstruction Benchmark
Abstract
We present MMTR-Bench (Multimodal Masked Text Reconstruction Benchmark) to evaluate native visual context reconstruction in complex multimodal inputs. Unlike traditional question-answering tasks, MMTR-Bench presents models with masked single- or multi-image inputs from diverse real-world scenarios, such as documents and webpages.
To solve the task, models must recover the hidden text by relying on the remaining layout structure, visual cues, and relevant world knowledge. By removing question-based guidance, this task challenges models to autonomously parse and reason over complex visual structures. The benchmark contains 2,771 test samples spanning multiple languages and varying target lengths. To fairly assess this diversity, we introduce a level-aware scoring mechanism. Extensive experiments on representative models demonstrate that MMTR-Bench remains highly challenging, particularly for sentence- and paragraph-level recovery.
Why MMTR-Bench
MMTR-Bench moves beyond question-guided evaluation and directly measures whether multimodal models can reconstruct hidden text from visual context, layout structure, and semantic cues.
No Explicit Questions
Models are not told what to look for. They must identify relevant evidence and recover the hidden target without task-specific prompts.
Beyond OCR Completion
Success depends on layout understanding, visual grounding, chart or table interpretation, and the ability to exploit contextual structure rather than local text matching alone.
Native Multimodal Reconstruction
Some cases require cross-region, cross-page, or world-knowledge-supported recovery, making the task closer to real multimodal perception and reasoning.
Benchmark at a Glance
MMTR-Bench covers diverse sources, multiple difficulty levels, and both local and cross-image reconstruction settings.
Benchmark Pipeline
From sample construction to automated scoring, MMTR-Bench evaluates masked text reconstruction with a level-aware and factuality-aware pipeline.
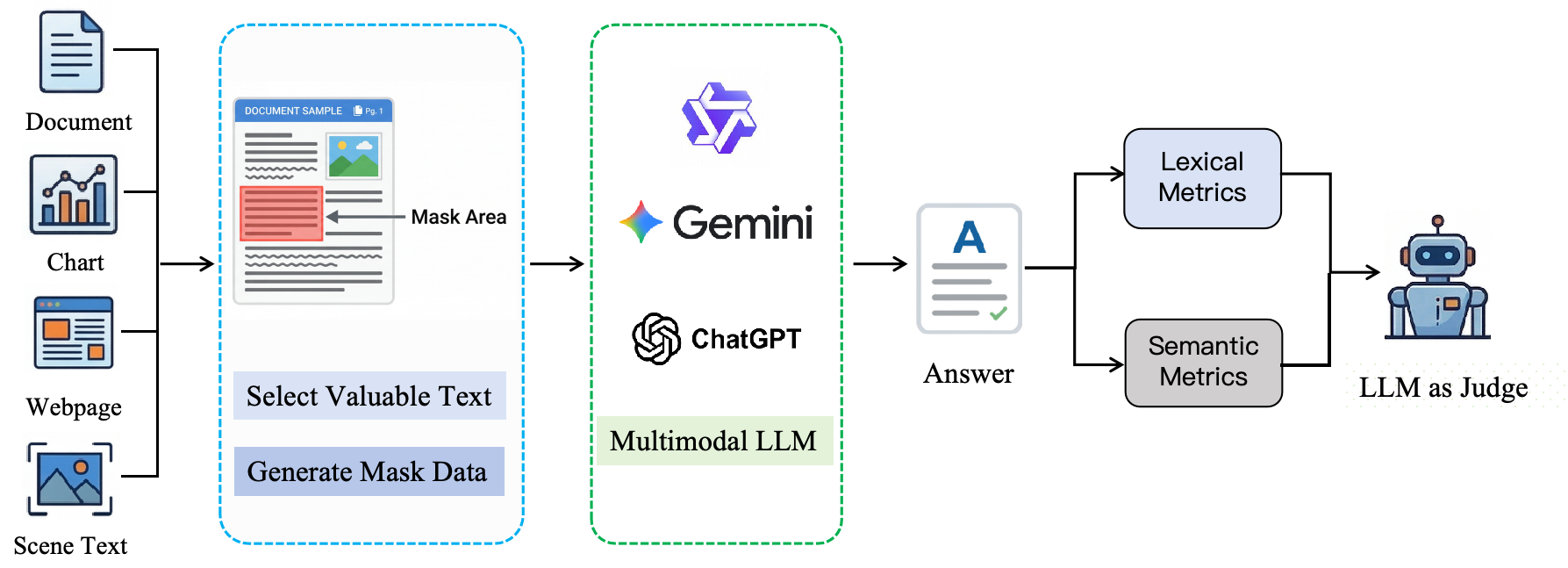
The pipeline consists of four stages: (1) Data Preparation, where informative text spans are selected and masked; (2) Inference, where multimodal models predict the hidden text; (3) Metric Calculation, where lexical and semantic metrics are computed; and (4) Automated Assessment, where an LLM-based judge applies factuality-aware scoring.
Dataset Overview & Results
MMTR-Bench covers documents, charts, tables, webpages, and other real-world multimodal inputs, with reconstruction targets ranging from short entities to long-form text.
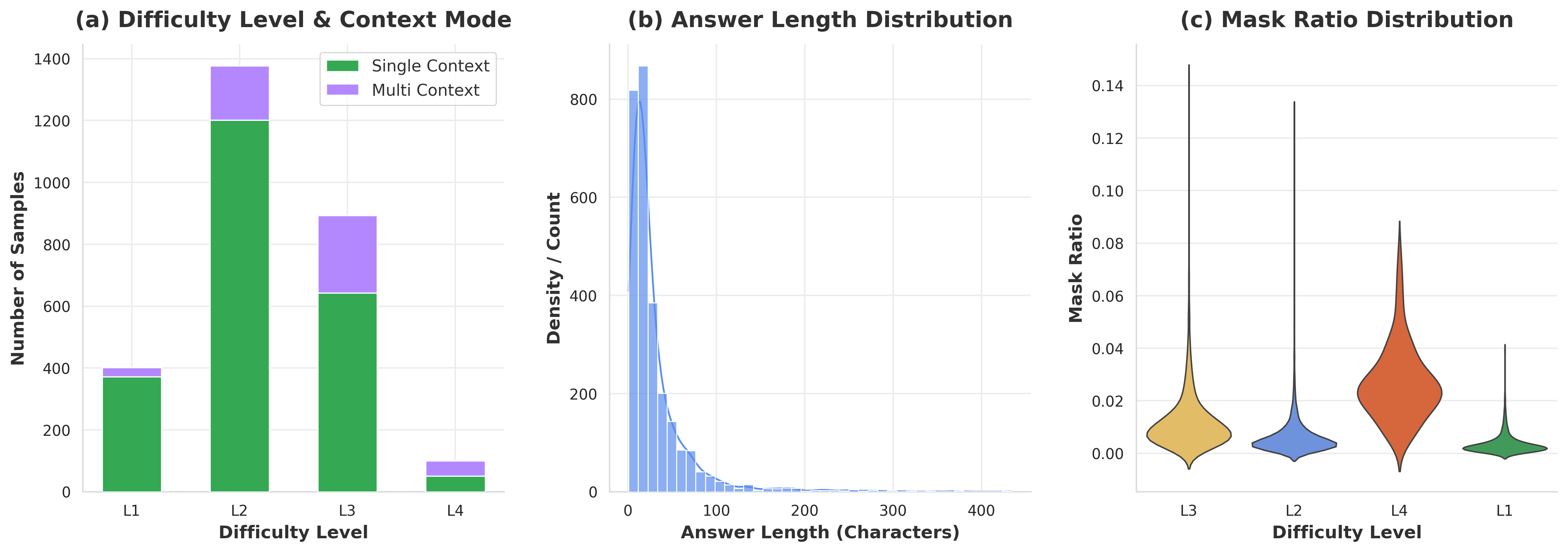
MMTR-Bench covers diverse sources and varied reconstruction difficulty, spanning single-image and multi-image inputs with multiple answer lengths and mask ratios.
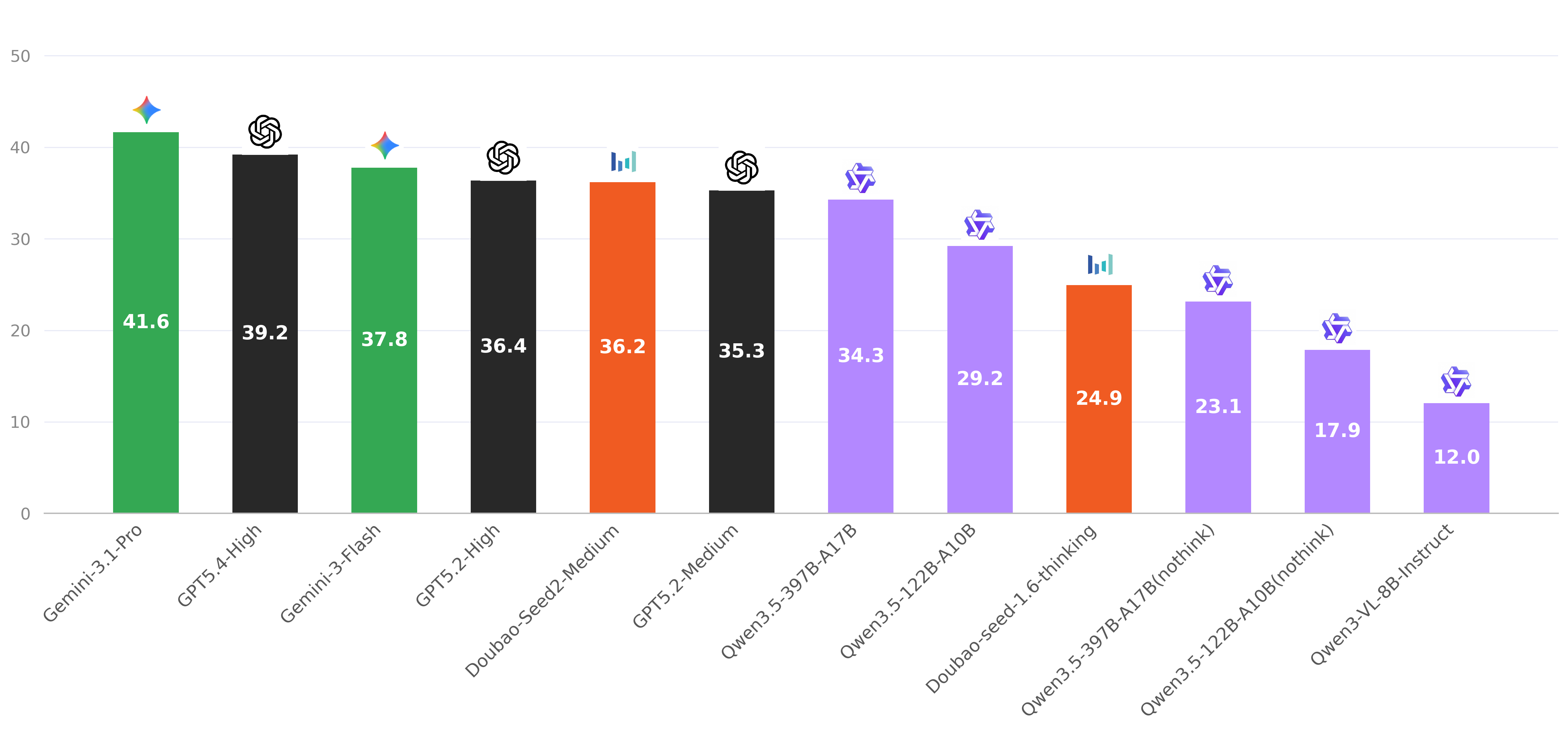
Results on representative MLLMs show that reconstruction remains challenging across all levels, especially for longer and more context-dependent masked targets.
Extended Case Studies from MMTR-Bench
Swipe to explore 32 diverse test cases spanning multiple difficulty levels, source types, and languages. In each example, the left panel shows the original input, and the right panel shows the masked version used for evaluation.


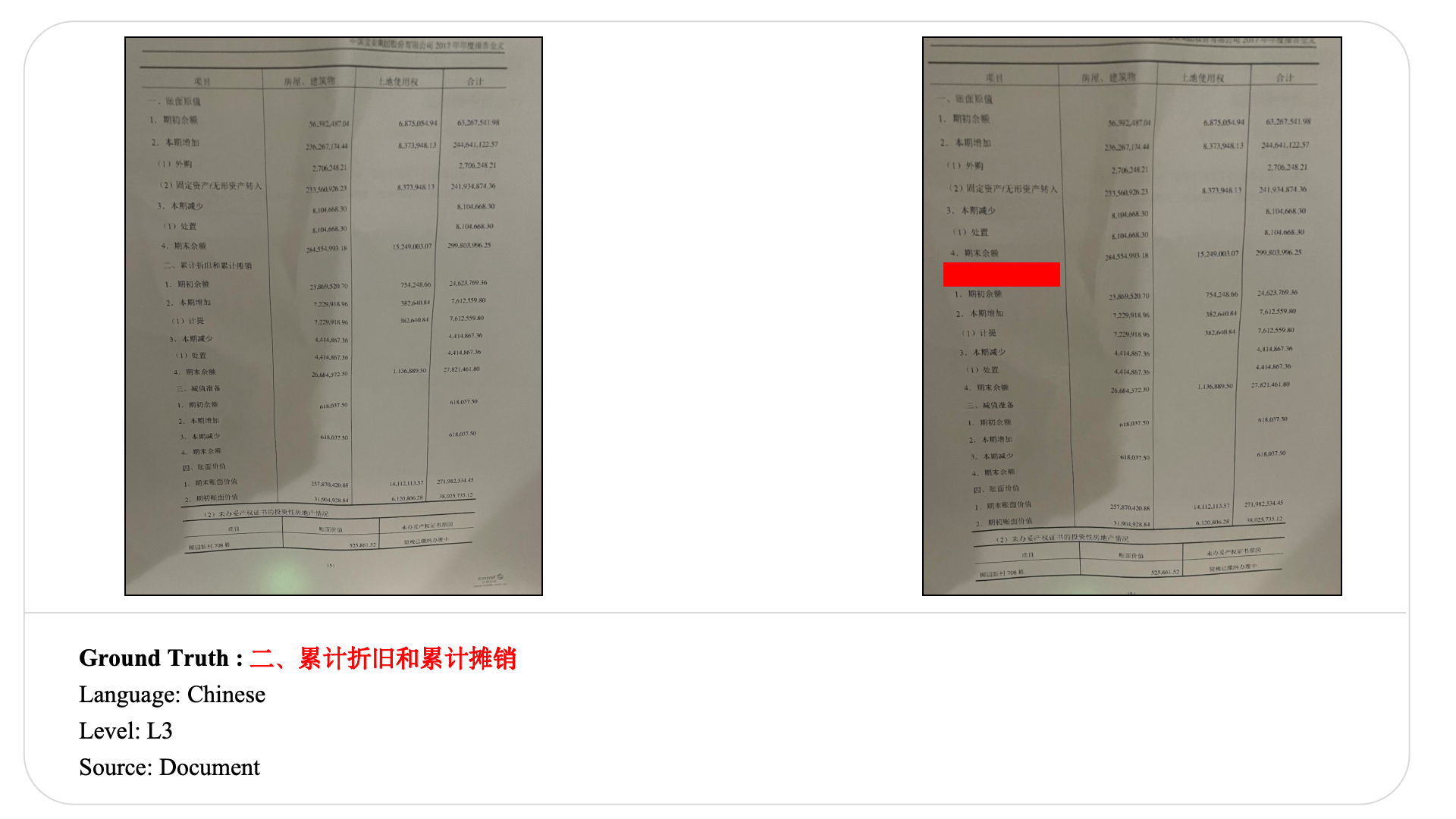




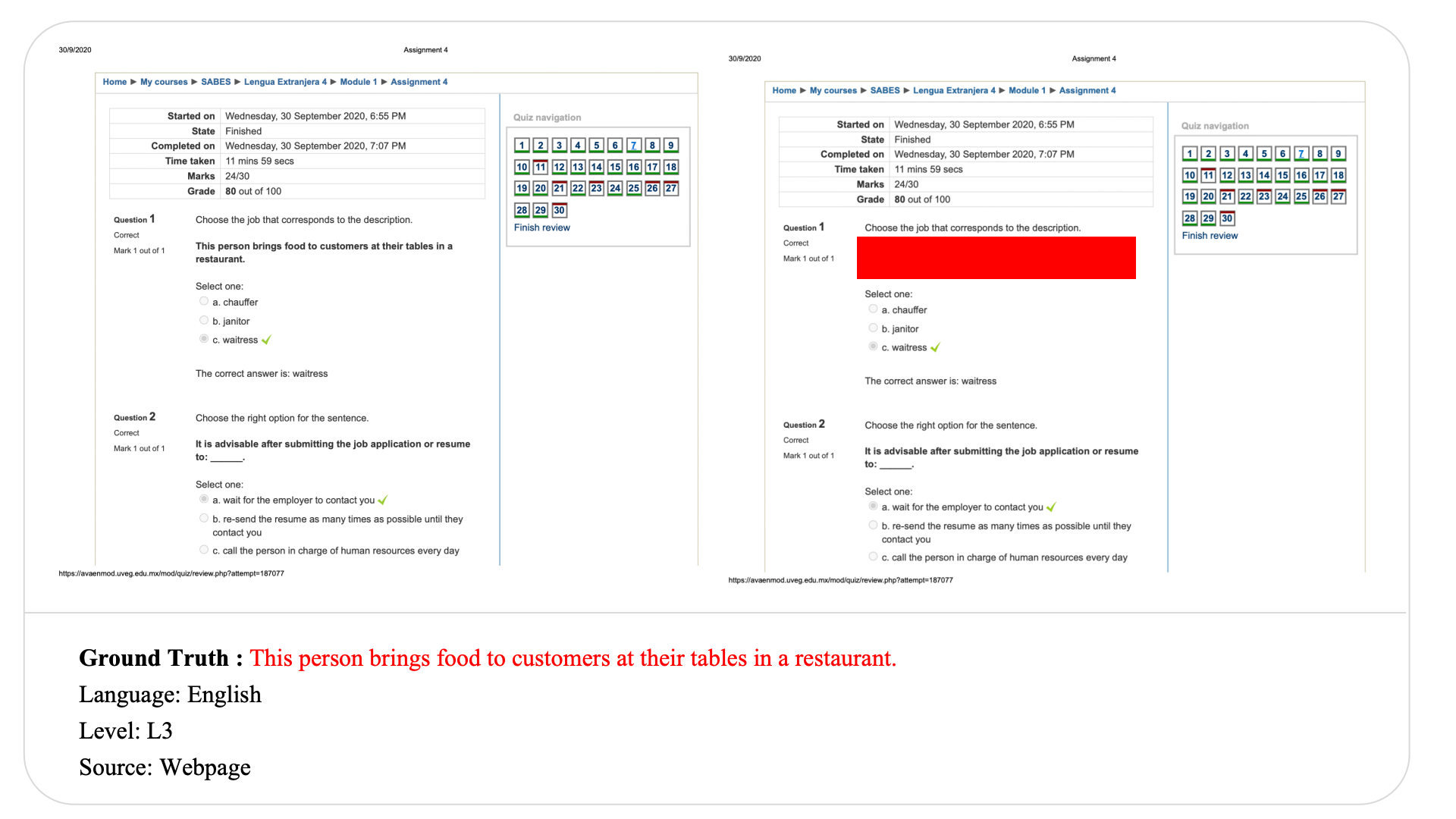

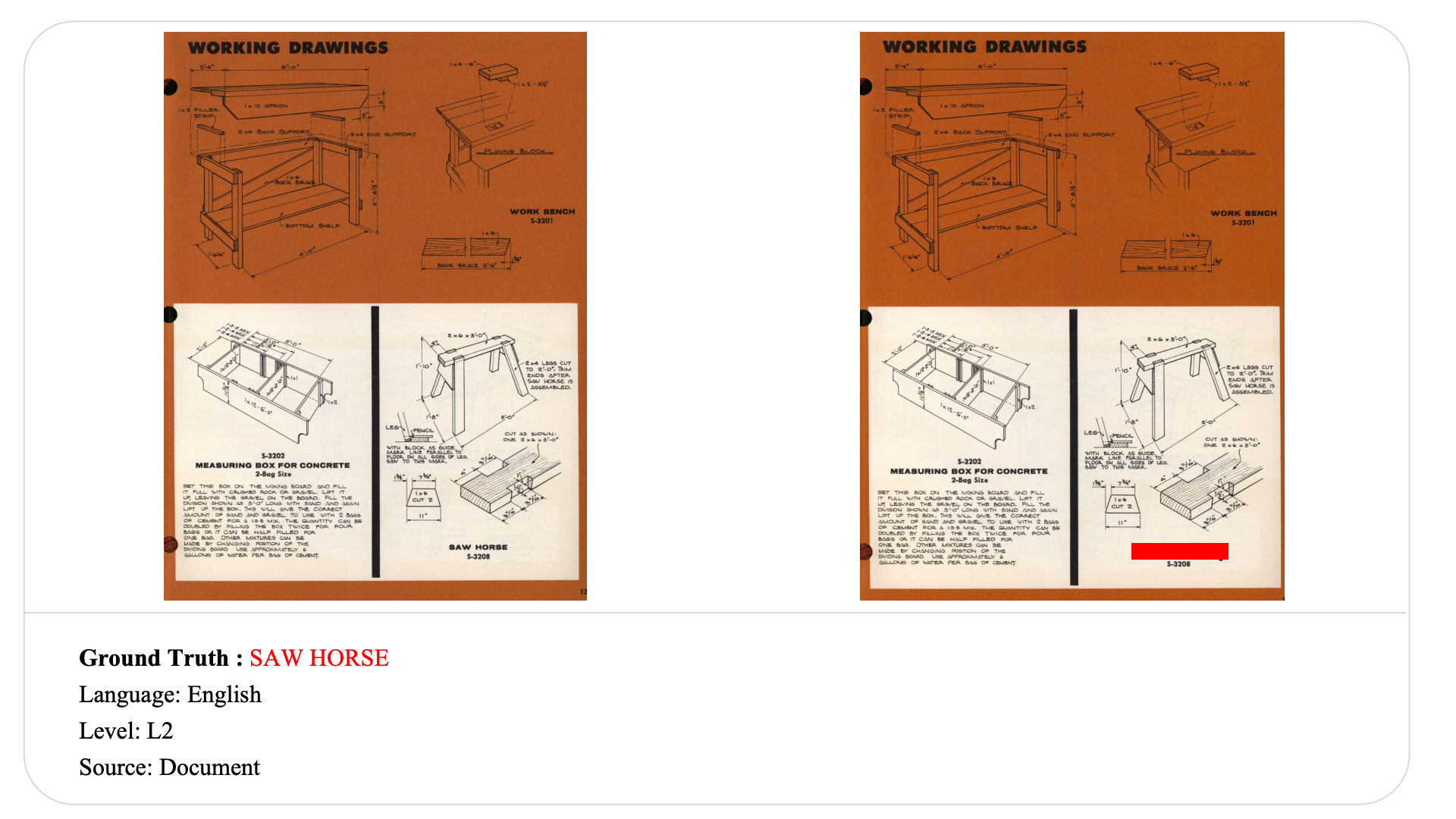



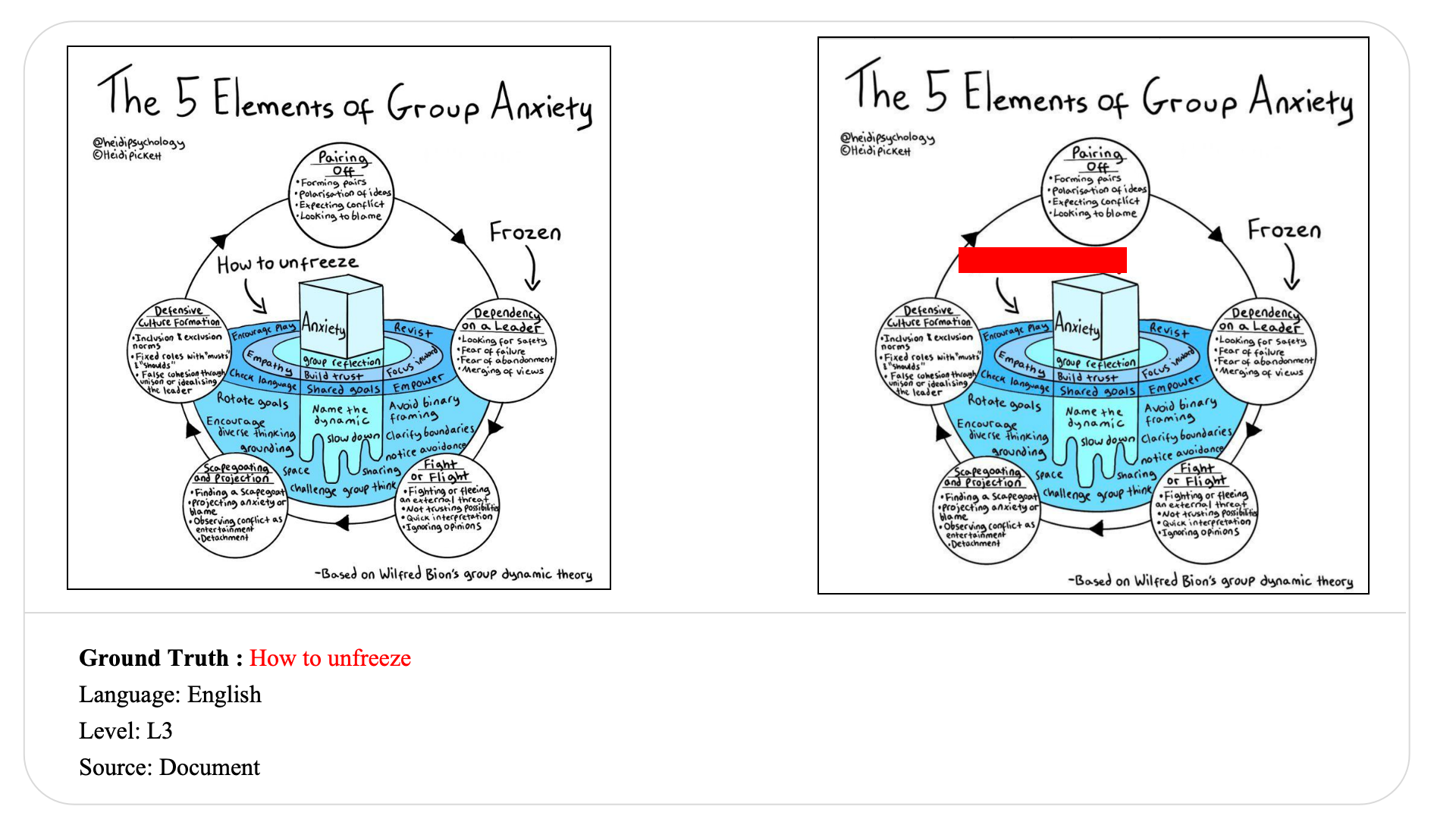
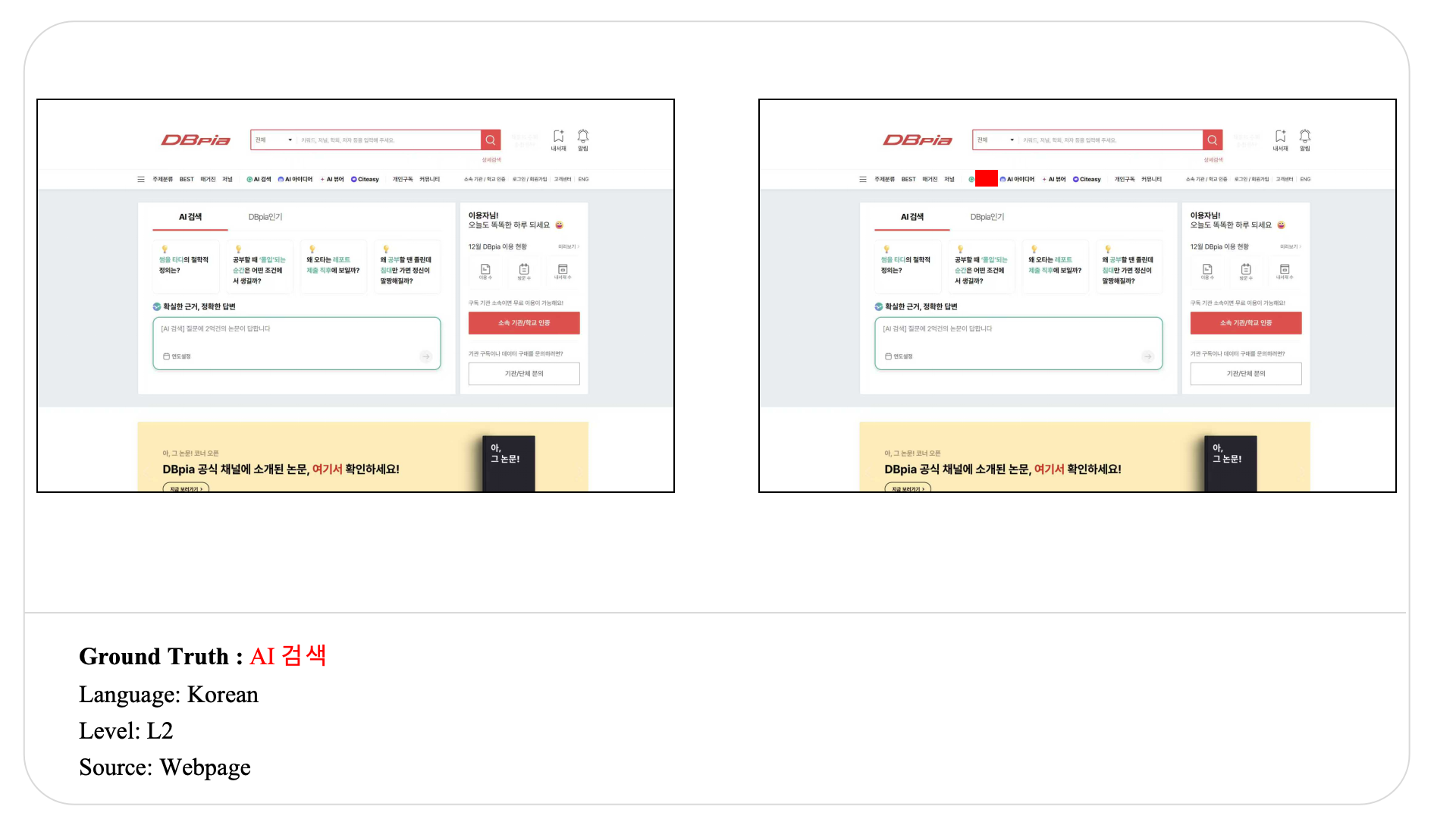
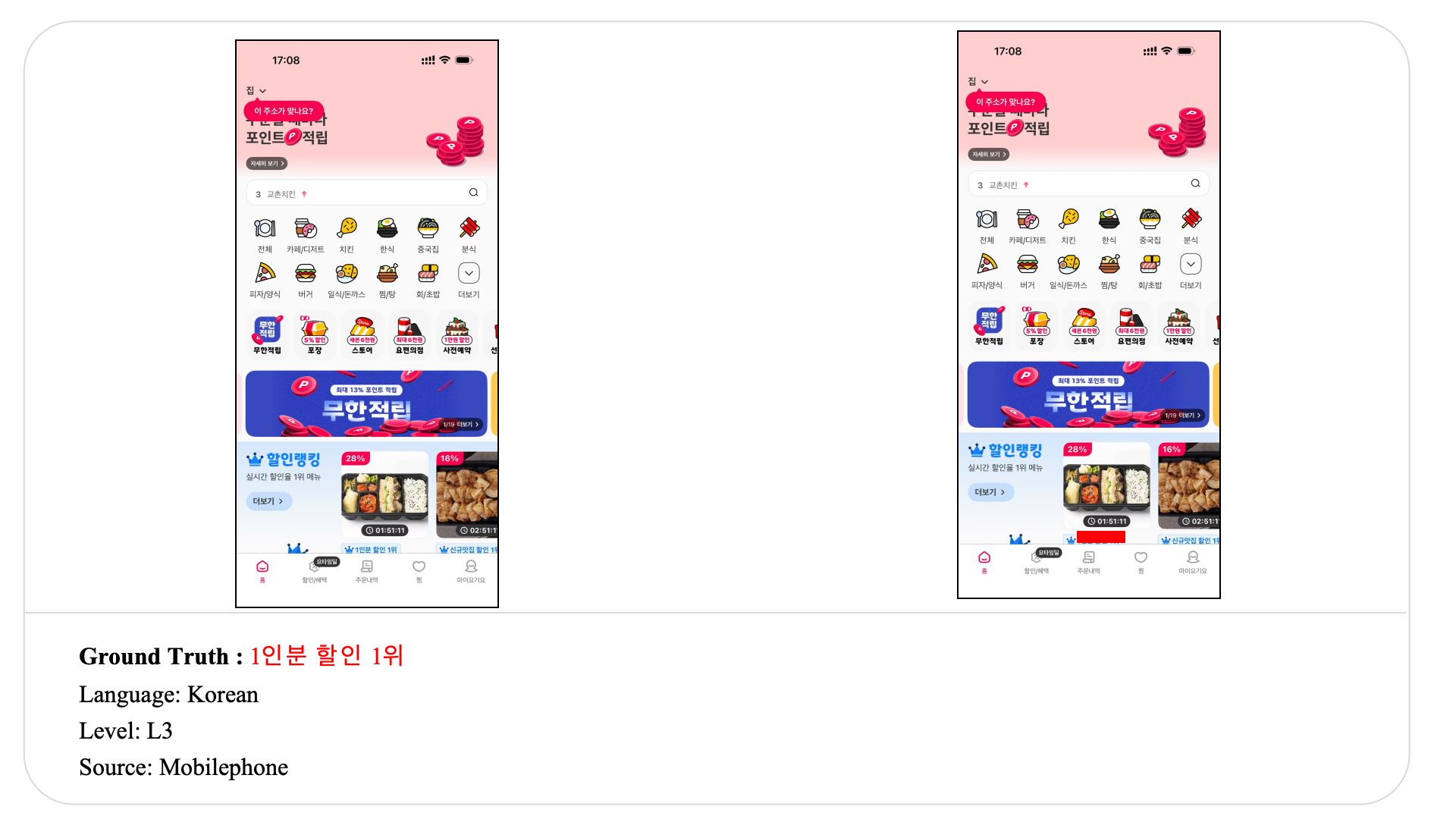
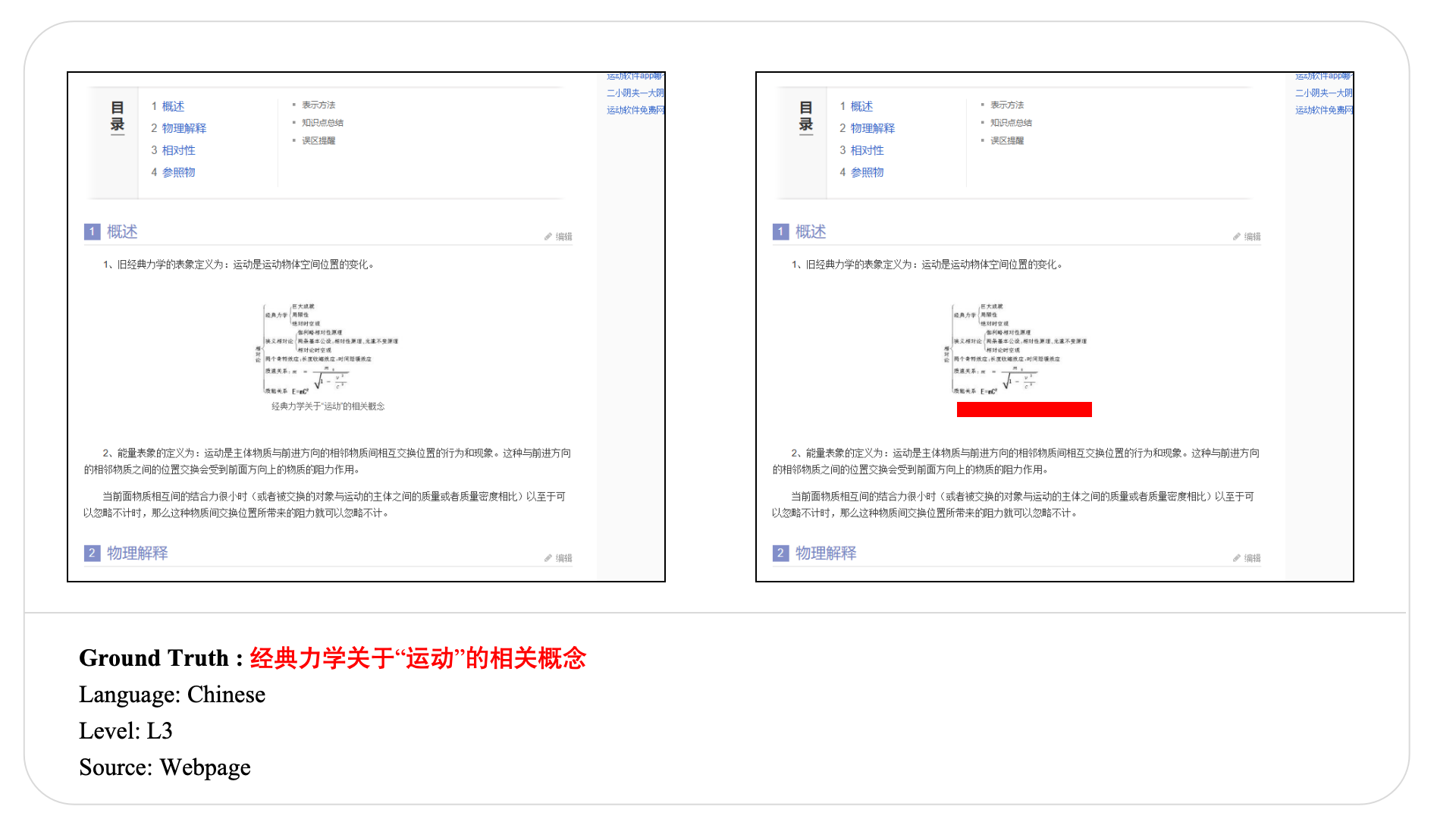
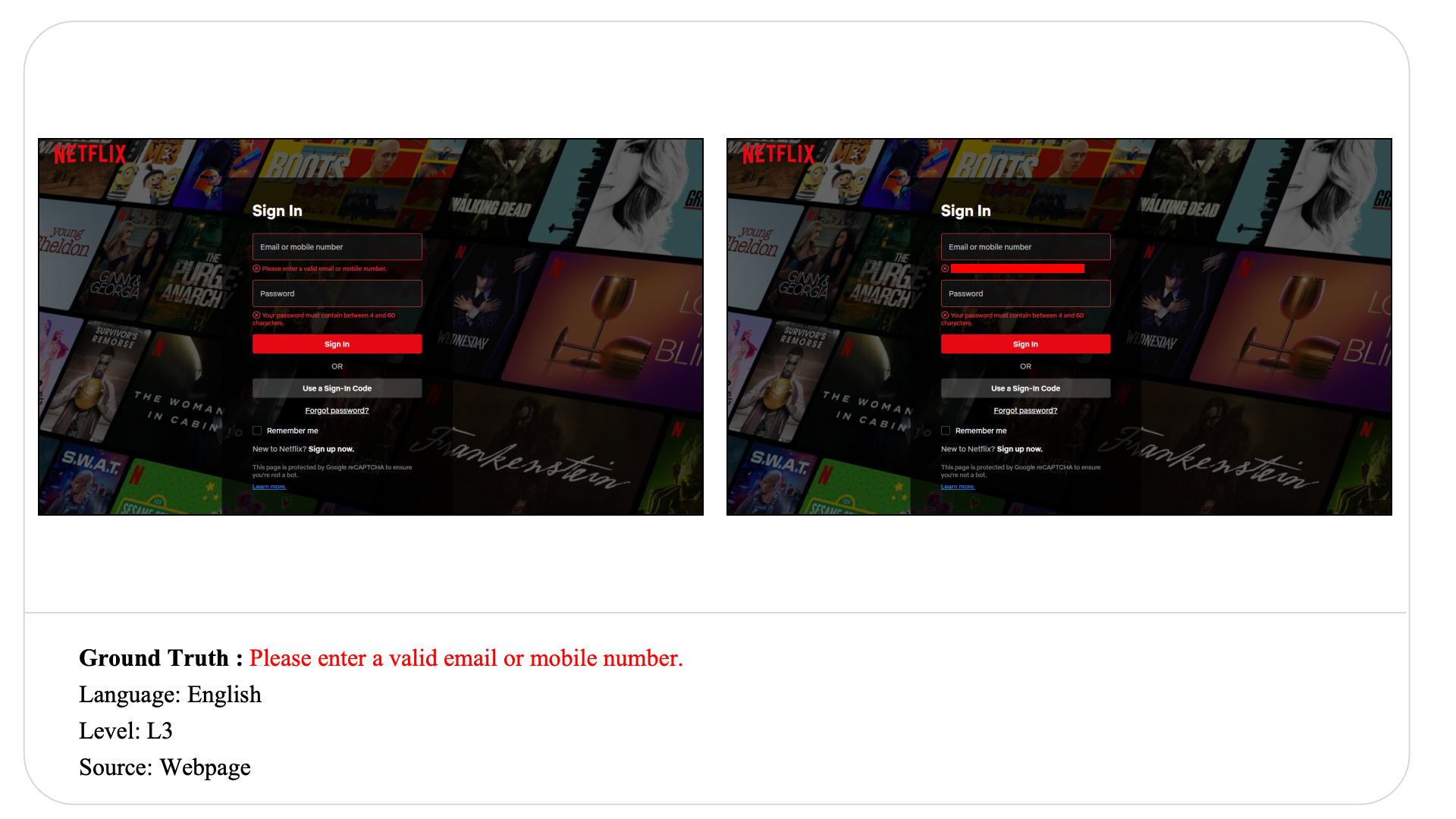
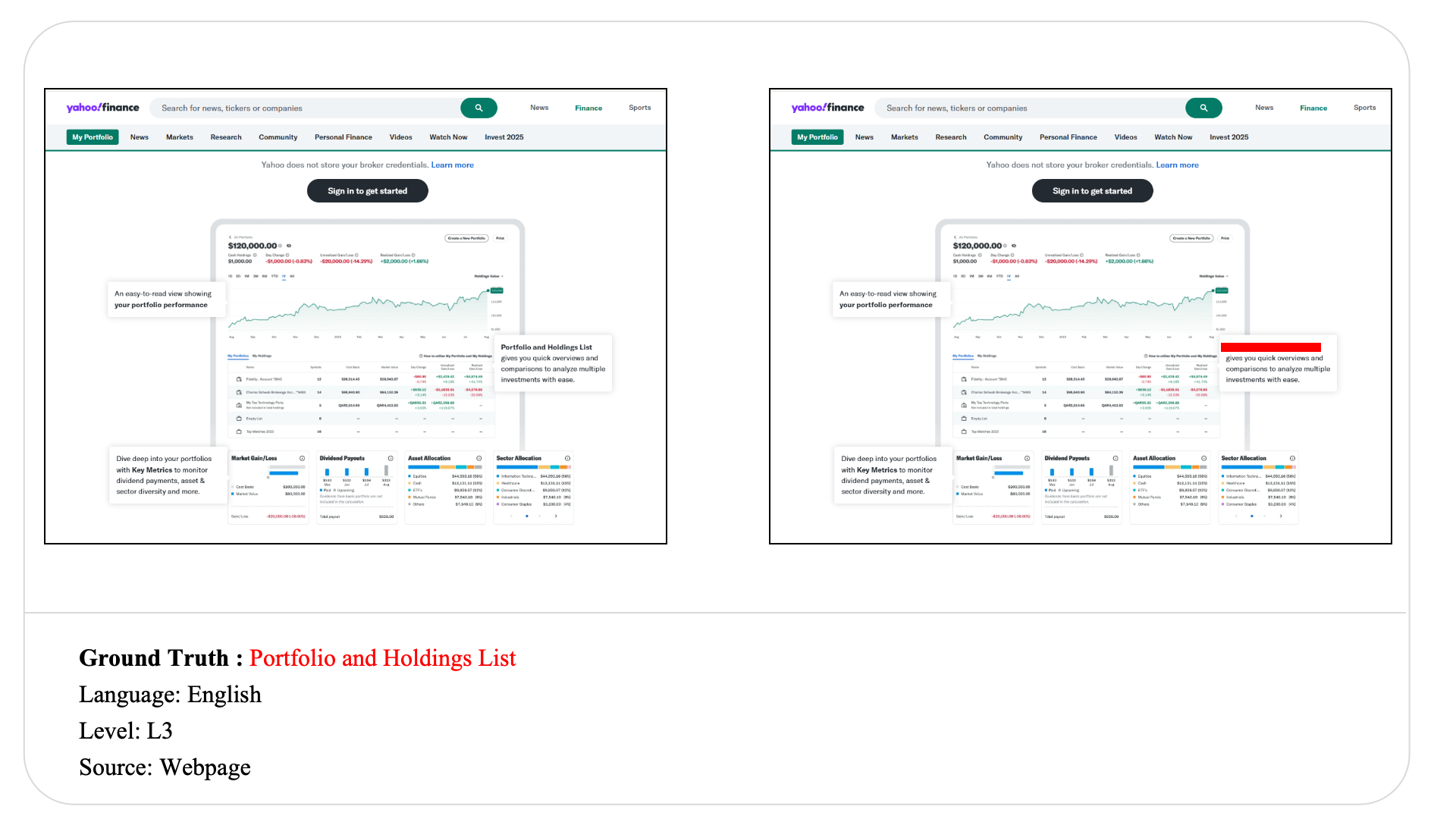
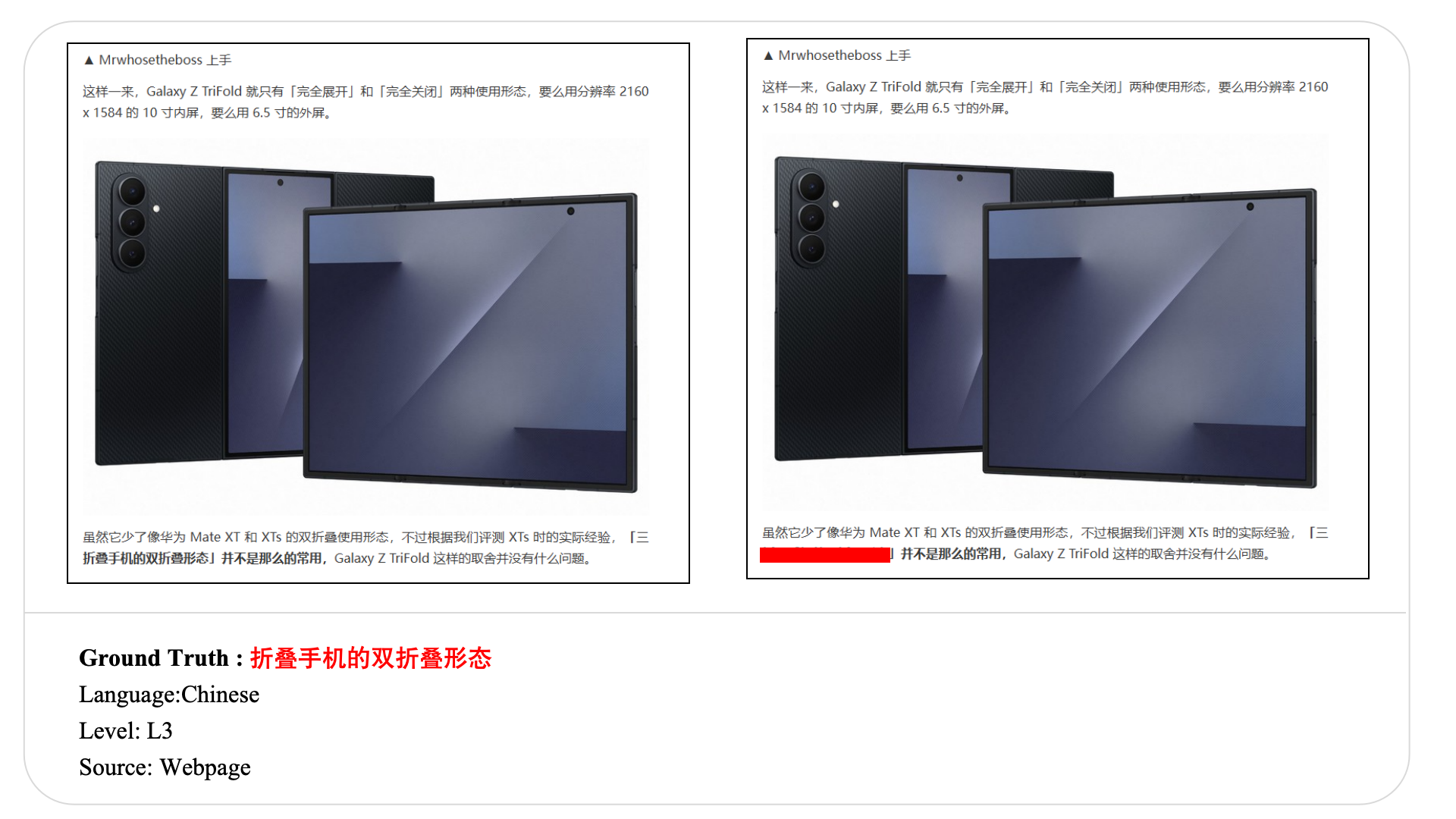

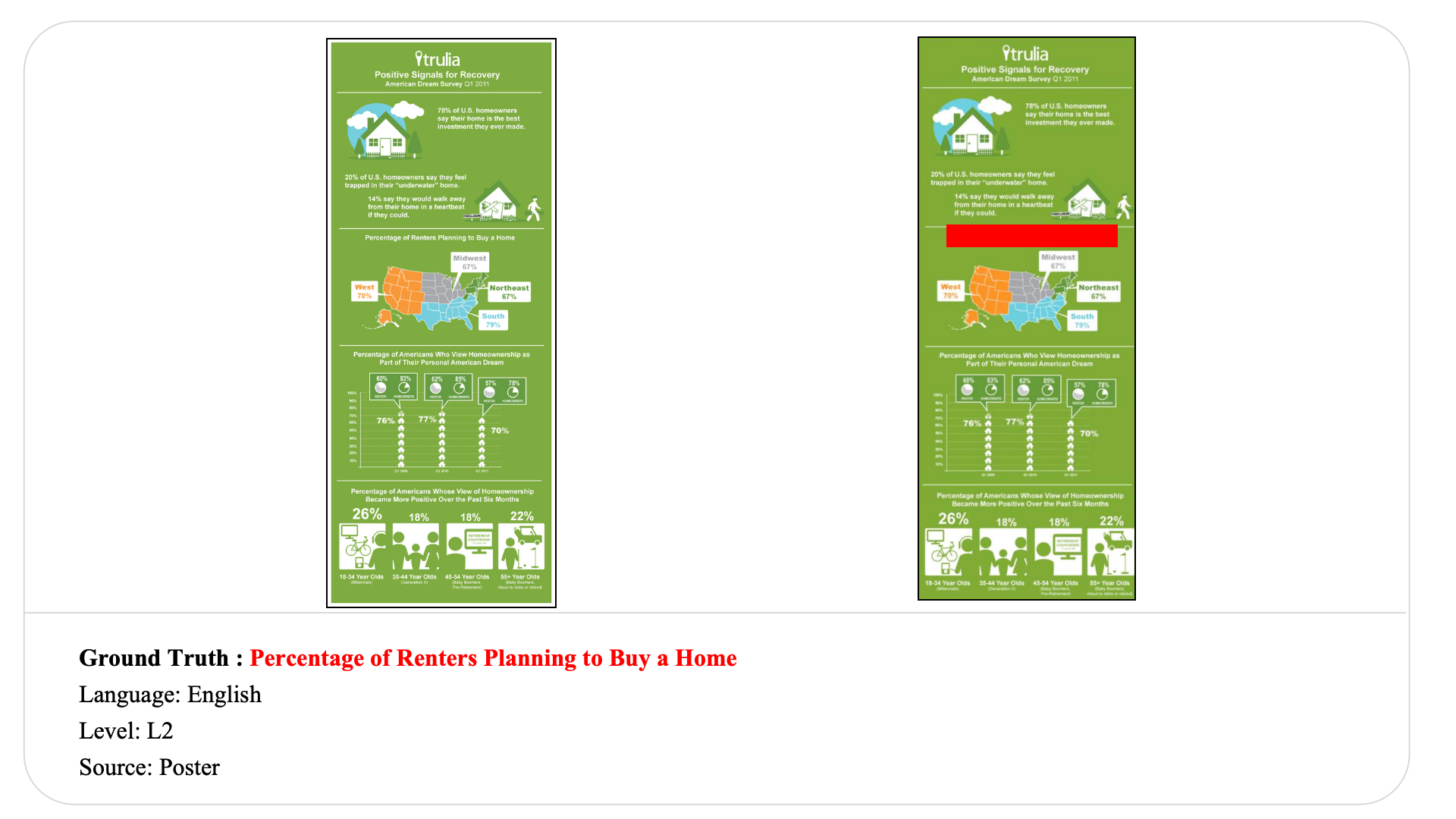
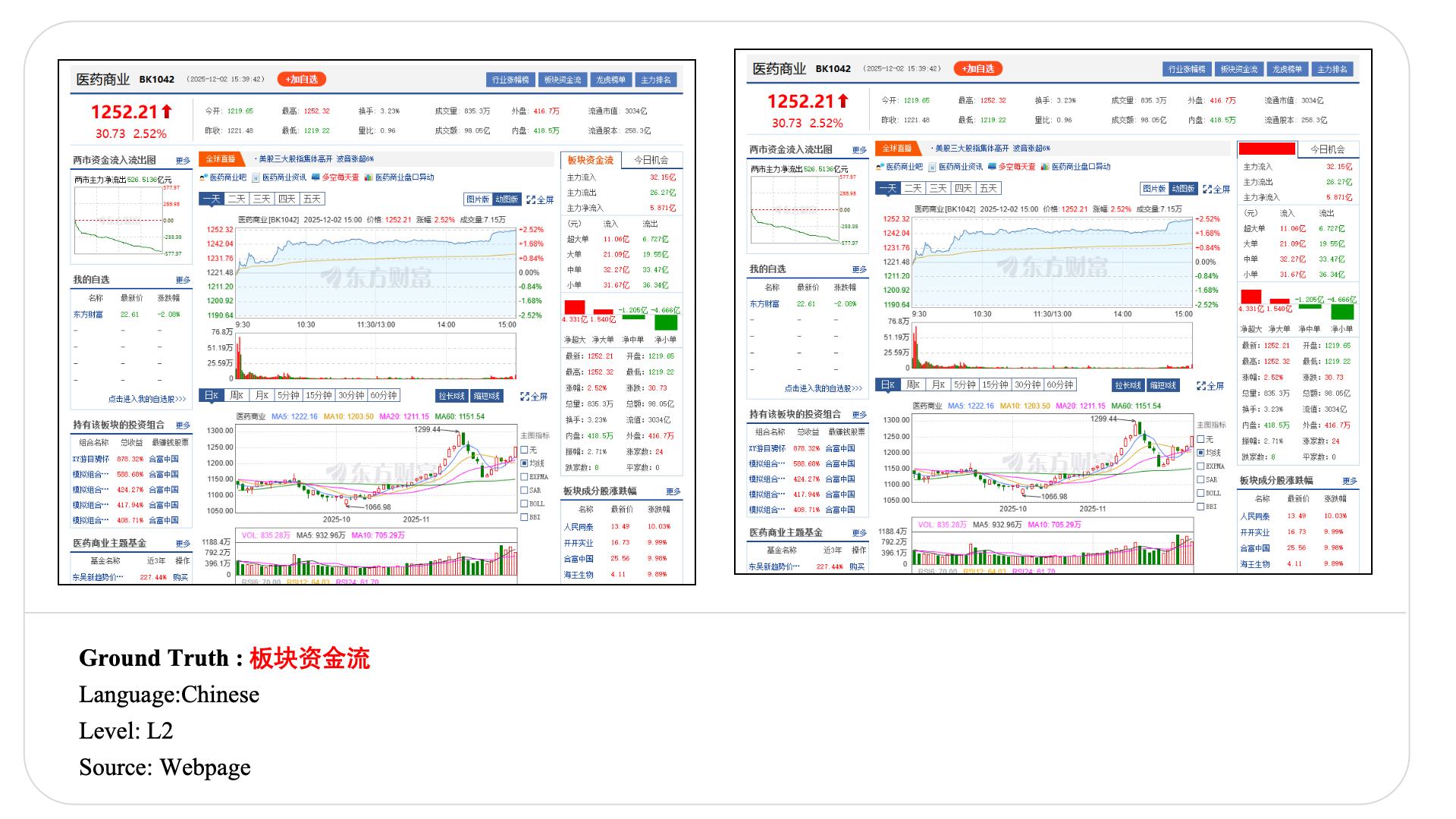

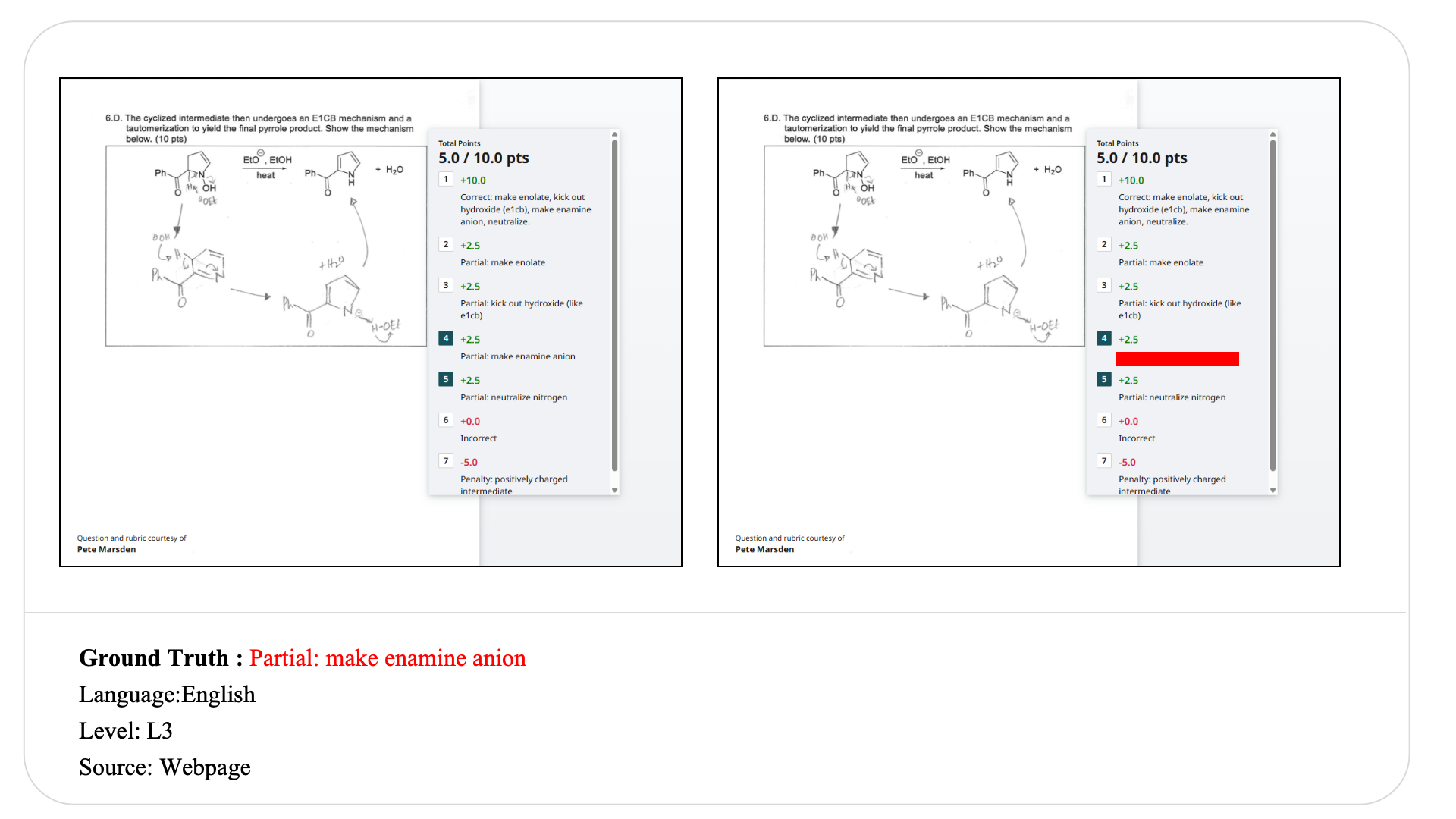
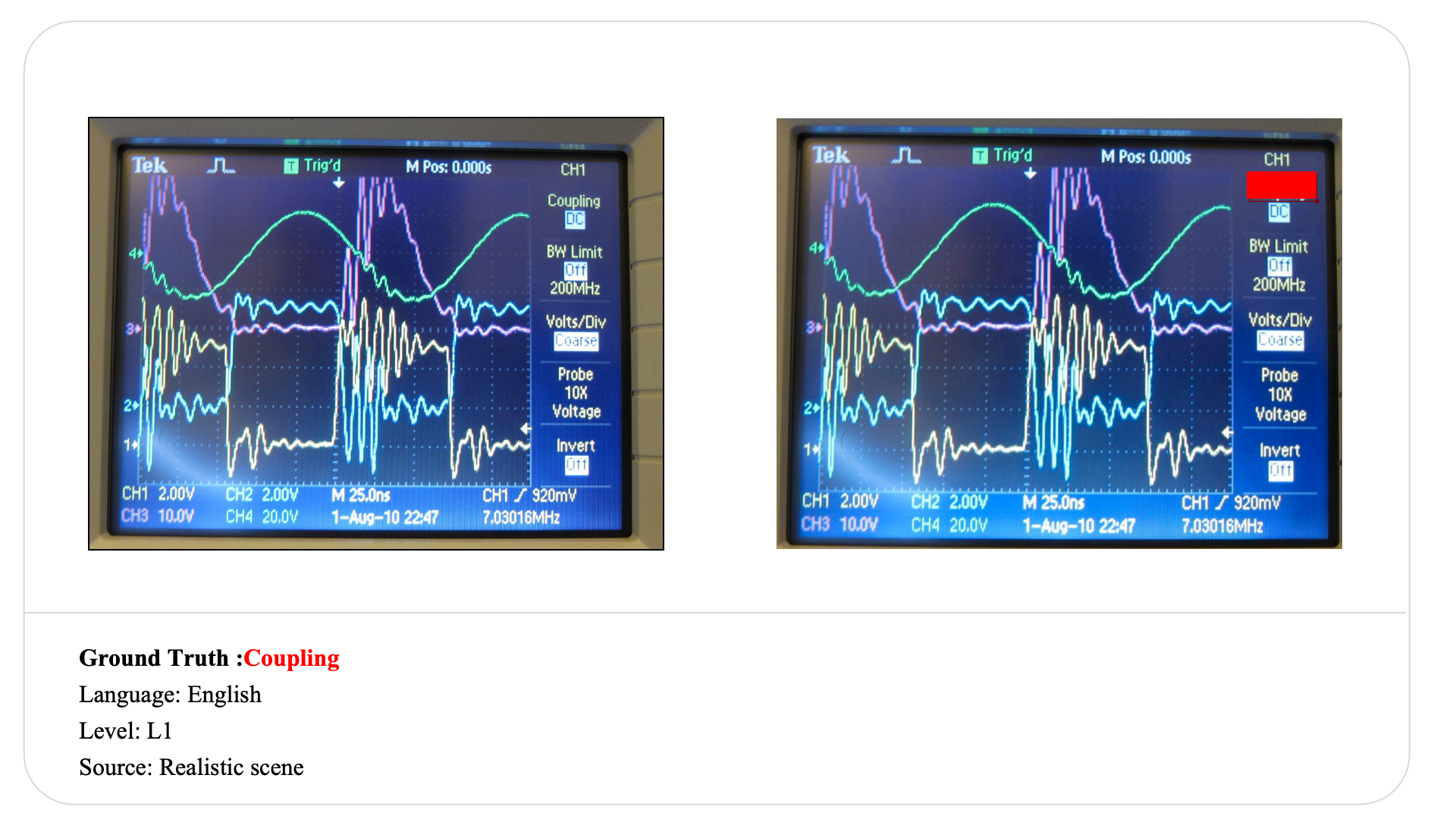
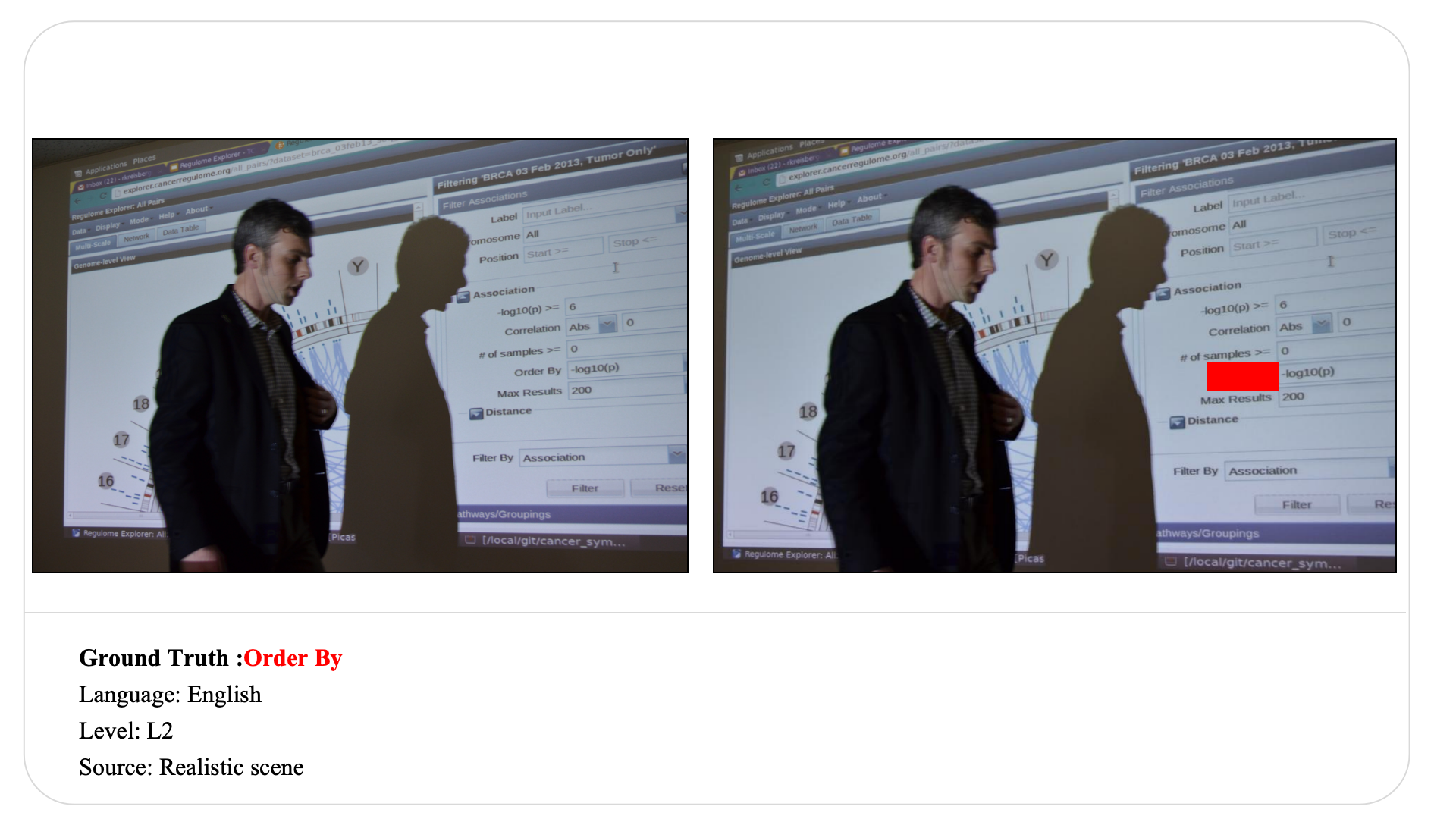



Case Studies and Error Analysis
The following examples highlight representative failure modes and a thinking-versus-non-thinking comparison under masked text reconstruction.
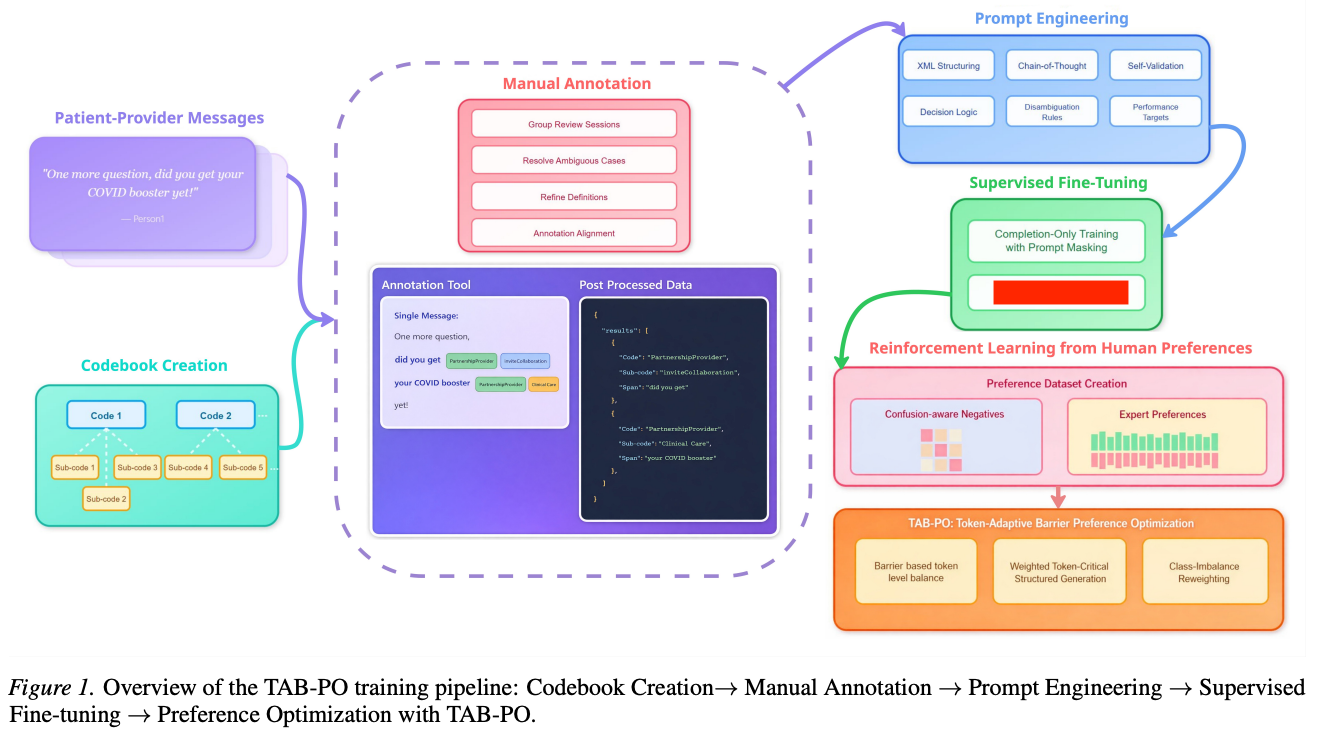
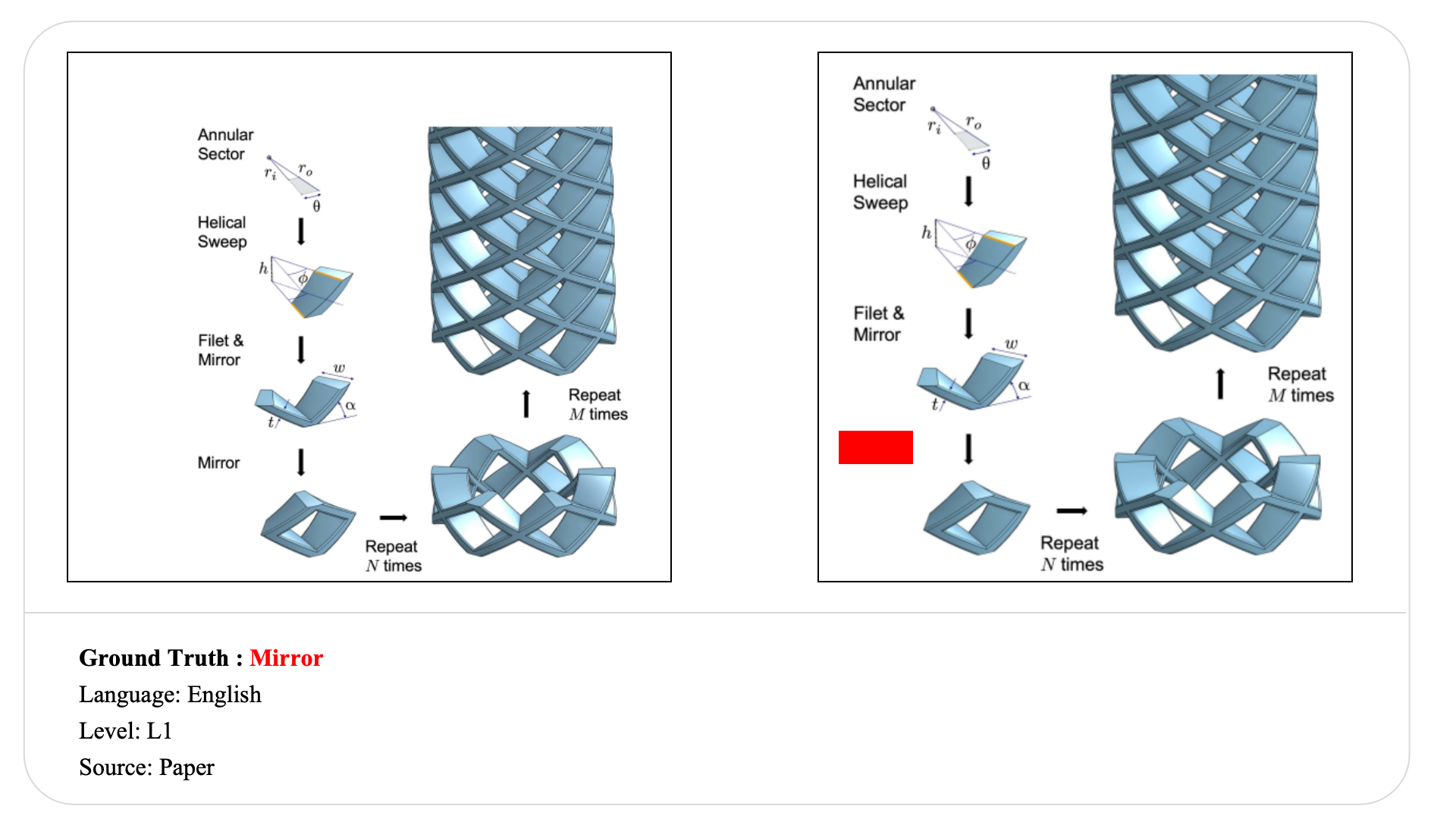
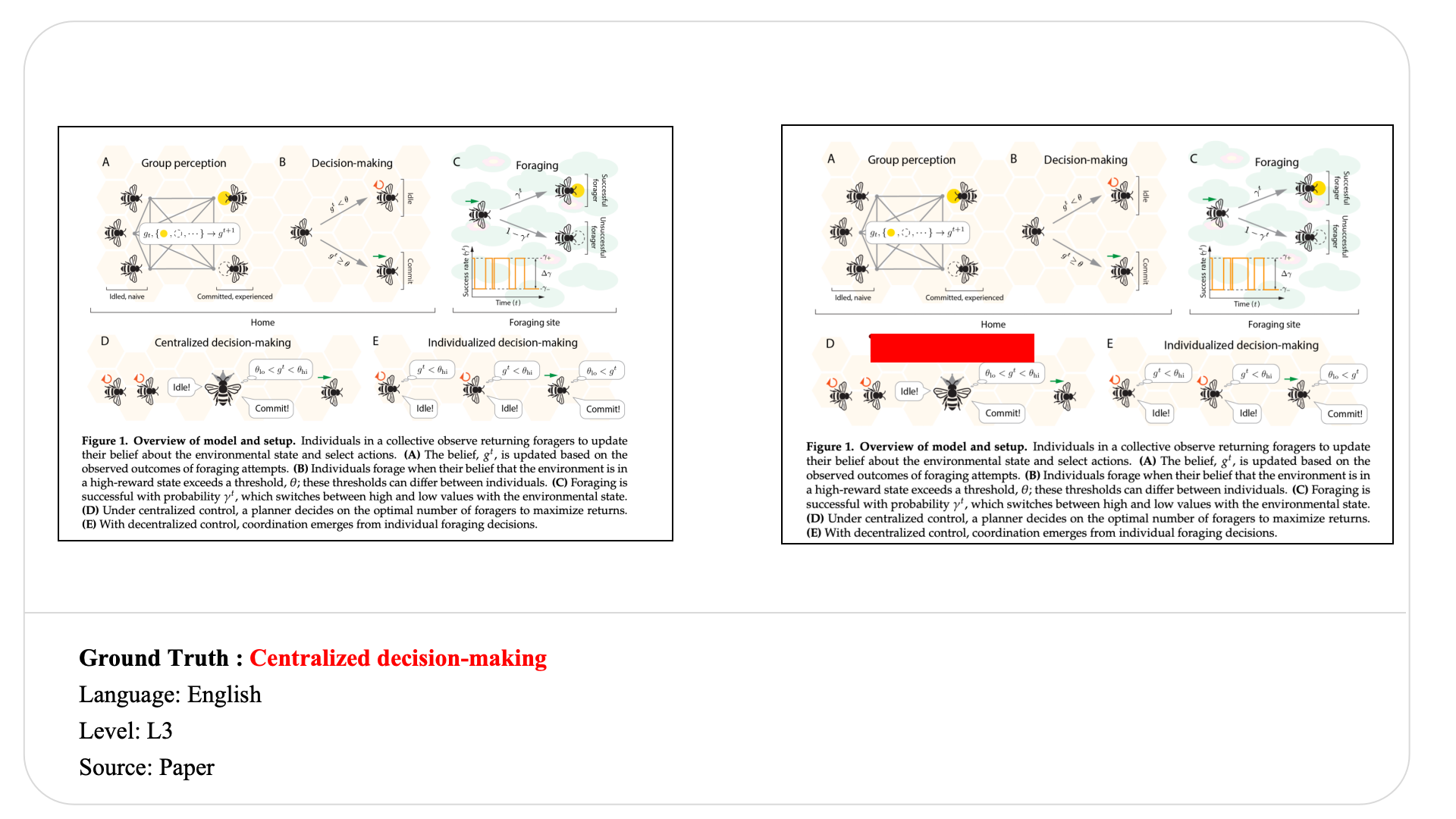
Visible-text copying in modular pipeline diagrams
Ground truth
Representative wrong predictions
- Instruction Fine-Tuning
- Low-Rank Adaptation (LoRA)
- Structured JSON Generation
- Completion-Only Training with Prompt Masking
Although the figure is visually clean and highly structured, models systematically fail to recover the exact hidden module name. Most predictions either copy nearby visible phrases or generate semantically plausible training-related terms. This reveals a gap between understanding the overall topic of a pipeline and reconstructing the precise hidden component.
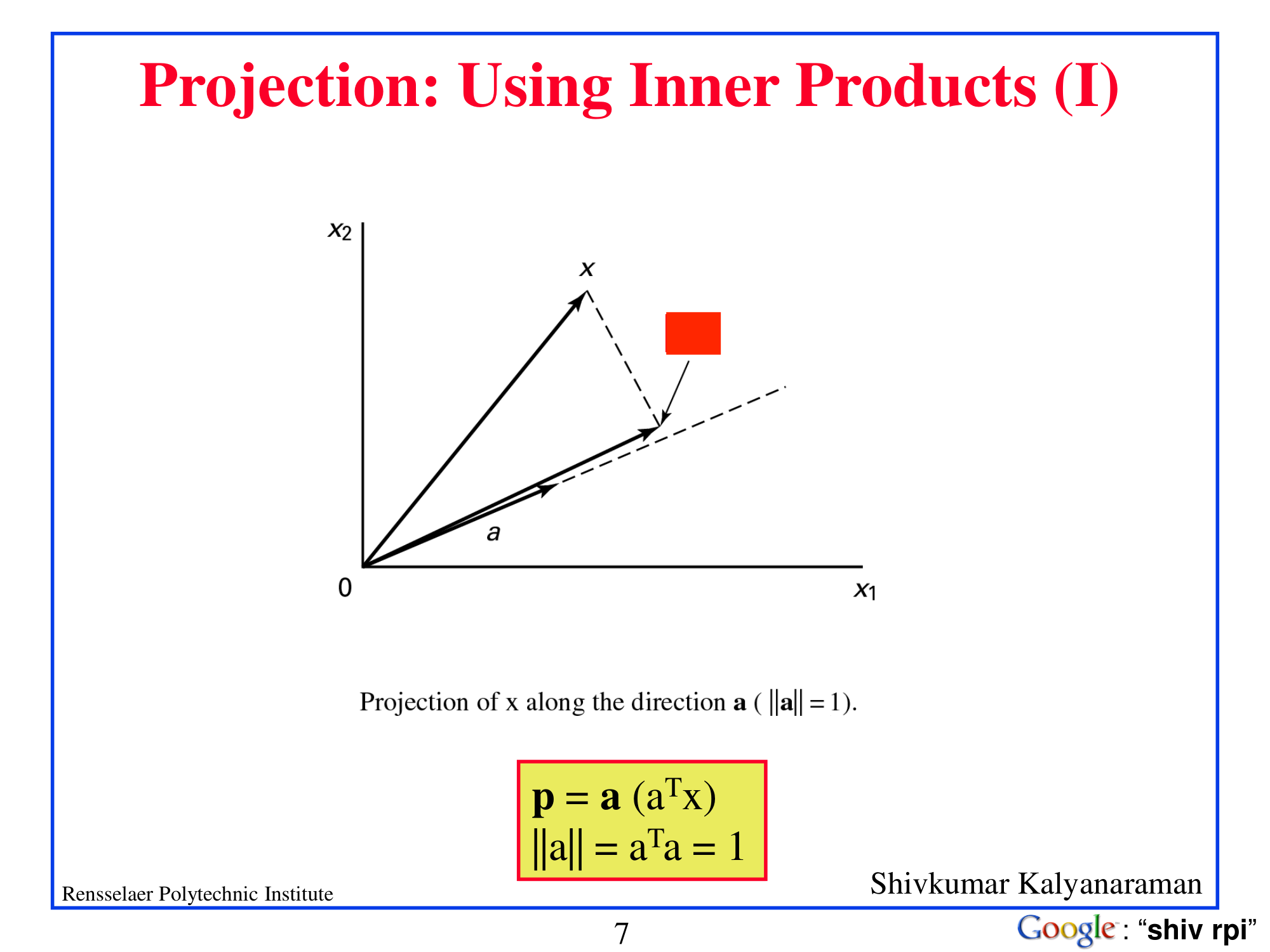
Symbol anchoring in mathematical diagrams
Ground truth
Representative wrong predictions
- p
- Projection of x along the direction a
- p = a(aTx), ‖a‖ = aTa = 1
Most models collapse to the nearby visible symbol p or copy a larger visible equation instead of reconstructing the hidden inner-product term. This example shows that topic-level understanding of a mathematical slide is not enough for exact formula-level recovery.

Reasoning helps when the target is structurally constrained
Ground truth
| Model family | Non-thinking | Thinking |
|---|---|---|
| Qwen3.5-122B-A10B | 0 | STRIKE |
In this case, the masked target is part of a scoreboard where the surrounding structure strongly suggests the template BALL–STRIKE–OUT. The non-thinking variant anchors on a nearby count value, while the thinking variant successfully recovers the hidden label by exploiting the local structural schema.
Abbreviated reasoning trace: identify the masked region as part of the scoreboard count panel, infer the conventional label order, and reconstruct the hidden text as STRIKE.
BibTeX
@article{mmtrbench2026,
title={MMTR-Bench: Multimodal Masked Text Reconstruction Benchmark},
author={Anonymous Authors},
journal={Under Review},
year={2026}
}